There are controversies in the VHDL community about how you can and shouldn’t use subprograms. Some say you should avoid using functions or procedures in synthesizable (RTL) code.
While there are debatable subjective reasons to restrict the use of subprograms, many of these beliefs stem from myths or misconceptions. Therefore, I’m writing this article to give you clarity and understanding of subprograms so you can decide for yourself.
TL;DR answers
Before explaining in detail, let me give the short answers to the most common questions regarding using subprograms instead of coding everything in a process.
Do functions and procedures use more logic resources?
No. A subprogram describes the same logic as the inline code it replaces.
Are functions and procedures bad for timing?
No. The timing characteristics are the same regardless if you use a subprogram or not to describe the logic.
Will a function or procedure call add registers/pipeline stages/use more clock cycles?
No. Not unless you made a mistake when writing the subprogram.
Are subprograms slower than inline code?
It can impact the simulation speed, but the synthesized hardware is unaffected.
VHDL is not a programming language
I think much of the misunderstanding comes when people who know regular programming start learning VHDL. Conventional programming languages have subroutines in the form of functions or methods, and when you call one, it introduces a slight overhead when data is pushed to and popped from the call stack.
But VHDL is not for creating computer programs.
Another thing that confuses learners is that VHDL serves two primary purposes: synthesis and simulation.
For synthesizable VHDL code, each additional subprogram call usually results in the generation of additional logic. The synthesis tool will use physical FPGA primitives to implement the logic each function or procedure call describes.
In simulation, on the other hand, the VHDL code runs like a parallel event-driven programming language. A function call is a function call because it’s just a simulation that produces no hardware. And subprograms may slow it down, depending on the simulator implementation.
But we are in the business of making hardware, which is unaffected by subprogram overhead. Therefore, I will make a case for why you shouldn’t care about minor simulation time increases.
Example module
To prove the claims about subprograms I’ve already made earlier in this article, we will implement an example module in three different but logically equivalent ways.
entity dut is
generic (vec_length : positive);
port (
clk : in std_logic;
rst : in std_logic;
vec : in std_logic_vector(vec_length - 1 downto 0);
vec_reversed : out std_logic_vector(vec_length - 1 downto 0)
);
end dut;
The listing above shows our demo module’s entity. It contains a clocked process that reverses the bit order of the input vector vec to the output vector vec_reversed. And I’ve added a vec_length generic constant to allow flipping vectors of any bit lengths.
Using a For loop
The first and most straightforward method of reversing the vector is using a For loop. This implementation will be our reference design as it doesn’t use subprograms.
VEC_REVERSE_PROC : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
vec_reversed <= (others => '0');
else
for i in 0 to vec_length - 1 loop
vec_reversed(vec_length - 1 - i) <= vec(i);
end loop;
end if;
end if;
end process;
Actually, the For loop is the only method I recommend if you really want to reverse the bits of a std_logic_vector. The function and procedure versions that follow are over-complicated. I wrote them specifically to prove my points about subprograms, not because they are good ways to reverse vectors.
Using a recursive function
To create an example with excessive numbers of function calls, I wrote the recursive function you can see below. It will swap two bits in the vector v every time we call it.
function swap(
v : std_logic_vector;
i : natural := 0)
return std_logic_vector is
variable r : std_logic_vector(v'range);
variable tmp : std_logic;
begin
r := v;
-- Swap two bits
tmp := r(i);
r(i) := v(v'high - i);
r(v'high - i) := tmp;
-- Recurse to swap the next two bits
if i < v'high / 2 then
return swap(r, i + 1);
end if;
return r;
end function;
This function is recursive because it calls itself on line 18 until it reaches the vector’s middle bits. At that point, it has swapped all the bits and returns the reversed vector to the original caller.
The recursive function does the same job as the For loop but with vec_length / 2 function calls. It should be great for our case study about function overhead in VHDL.
VEC_REVERSE_PROC : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
vec_reversed <= (others => '0');
else
vec_reversed <= swap(vec);
end if;
end if;
end process;
Finally, we replace the For loop in the process above with a call to our swap() function. When we call it without providing an i argument, it defaults to 0, as specified in the function declaration. That will cause it to start with the outermost bits of the vector and recurse until it has reversed the whole vector.
Using a recursive procedure
The recursive swap() procedure is similar but operates on the vector signal’s bits—something a procedure can do and a function cannot.
procedure swap(
signal v_in : in std_logic_vector;
signal v_out : out std_logic_vector;
constant i : natural := 0) is
begin
-- Swap two bits
v_out(v_in'high - i) <= v_in(i);
v_out(i) <= v_in(v_in'high - i);
-- Recurse to swap the next two bits
if i < v_in'high / 2 then
swap(v_in, v_out, i + 1);
end if;
end procedure;
We must also replace the function call with a call to the procedure, as shown by the highlighted code line below. It takes the input and output signals as arguments.
VEC_REVERSE_PROC : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
vec_reversed <= (others => '0');
else
swap(vec, vec_reversed);
end if;
end if;
end process;
Synthesis
I ran all three variants of our demo module through Xilinx Vivado’s synthesis tool. And I can confirm that it produces identical netlists for the For loop implementation, the recursive function, and the recursive procedure.
I’ve set the vec_length generic to 5, which makes the schematic you can see below. A larger value will produce the same pattern but with more wires and flip-flops.
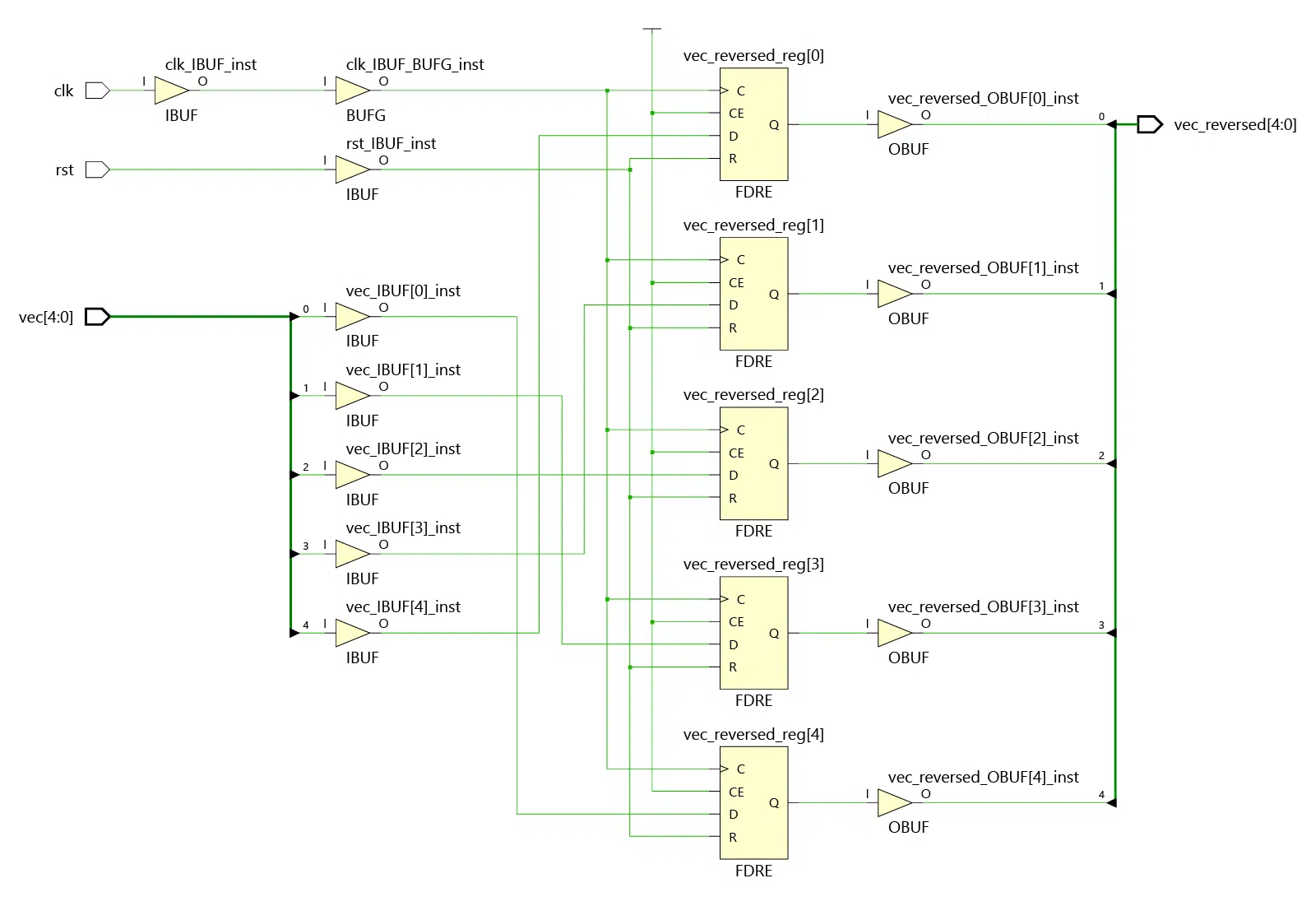
From this, we can conclude that function and procedure calls have no adverse effects on the synthesized netlist. And since the output from place and route (PAR) also will be identical, we know that it doesn’t affect timing either.
However, these statements are only valid if the synthesis tool does the job correctly. If you write a complex hierarchy of subprograms, it may be that a less accurate synthesizer won’t understand what you are trying to create.
Therefore I don’t recommend writing excessively creative code with or without subprograms. You can use functions and procedures in RTL code, but being conservative about how you code is a good idea.
Simulation
A VHDL simulation ultimately runs on a CPU because the simulator is a software tool on our computer. Since VHDL is now running like software, we can expect the same effects from subprograms as functions have on programming languages.
Let’s put it to the test and get a benchmark of how significant the slowdown is.
Testbench
We will use the testbench process shown below, which we will run on the Questa/ModelSim and Xilinx Vivado (Xsim) simulators. And we will test each implementation of the vector reversing module and measure the simulation run time in seconds.
With vec_length set to 256 and the simulation running for 1 million clock cycles, it means 128 * 1e6 = 128e6 (128 million) recursive function or procedure calls. Any adverse effects on run time should be measurable.
SEQUENCER_PROC : process
variable seed1, seed2 : integer := 999;
impure function rand_slv(len : integer) return std_logic_vector is
variable r : real;
variable slv : std_logic_vector(len - 1 downto 0);
begin
for i in slv'range loop
uniform(seed1, seed2, r);
slv(i) := '1' when r > 0.5 else '0';
end loop;
return slv;
end function;
begin
wait for clk_period * 2;
rst <= '0';
wait for clk_period * 10;
for i in 1 to 1e6 loop
vec <= rand_slv(vec'length);
wait for clk_period * 1;
end loop;
finish;
end process;
Measuring simulation run time
To measure the run time in Questa/ModelSim, I created this Tcl script which will run the simulation and print the total run time in milliseconds:
vsim -gui -onfinish stop work.subprog_overhead_tb
set t1 [clock milliseconds]
run -all
set t2 [clock milliseconds]
expr $t2 - $t1
The Xilinx Vivado Xsim simulator prints the run time to the transcript window after each simulation, so I used this information (CPU time) to populate the results table:
run: Time (s): cpu = 00:01:34 ; elapsed = 00:01:45 . Memory (MB): peak = 2050.234 ; gain = 0.000
xsim: Time (s): cpu = 00:01:37 ; elapsed = 00:01:52 . Memory (MB): peak = 2050.234 ; gain = 0.000
Results
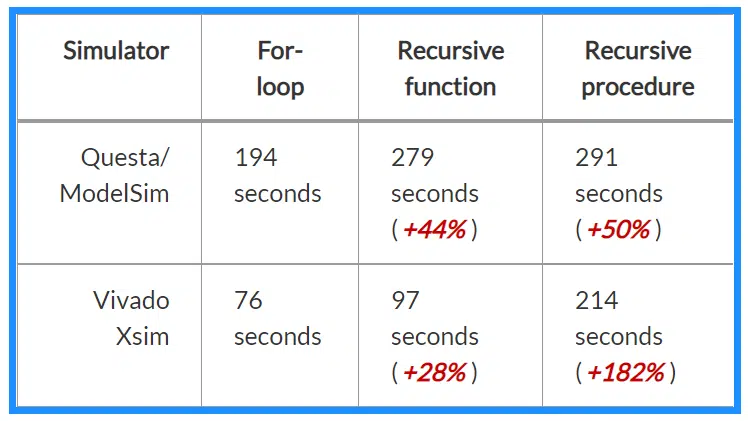
I used the Questa-Intel FPGA Starter Edition, which is significantly performance-restricted due to it being a free version. You can expect it to be much faster if you have access to a paid Questa or ModelSim version.
Vivado’s free built-in Xsim simulator isn’t restricted (to my knowledge).
Please note that three individuals conducted the tests on three different computers. Therefore, you can’t use these benchmarks for comparing simulator performances.
The chart shows how function and procedure calls affect each simulator.
* Thanks to Alejandro from the comment section on LinkedIn for providing the numbers for the paid version of Synopsis VCS! 👏
† Thanks to Emmanuel Poitier for providing the Riviera Pro v2022.04 results! 👏
As we can see from the run time results table above, the For loop is faster in Questa and Vivado.
The recursive function performed 44% worse than the For Loop in Questa/ModelSim, and the run time in Vivado was 28% higher.
The recursive procedure performed the worst of all. However, in Questa/ModelSim, the run time was only 50% higher than the baseline For loop, while in Vivado, it was 182% slower.
When considering these numbers, keep in mind that my demo module used excessive numbers of function and procedure calls. For each clock cycle, the recursion resulted in the subprograms being called 128 times. Any sensible VHDL design would have fewer subprogram calls, and the slowdown would also be much lower.
Conclusion
Functions and procedures are well-suited for synthesis and not bad for timing in any way. That’s because the netlist will be identical, regardless if you used a subprogram or wrote all the code in a process.
However, you must ensure that the subprogram describes the same logic as the inline code it’s replacing. Otherwise, the implemented design will be different, as well as the timing characteristics.
Finally, we saw that function and procedure calls can cause the simulation to run slower. But reasonable use of subprograms will likely only marginally affect the simulation speed.






Hi Jonas,
i don’t know if it is true but this is the first comparison between different tools i could find on the internet (which as far as I understand was not even the purpose of this article 🙂 ) ! The results are comparable with our internal measurements. I would like to give the TB a go also with active-hdl and modelsim de but i am missing how the dut is instantiated and how its output is used in the TB. Could you send me this information? Thanks.
Hi, Aleks. I sent you the files in an email. I haven’t prepared it for distribution, so there will be some commented-out code and such. But it should work.